Данная статья перевод текста Get All Your Search traffic With Google Search Console API (With Code Sample) с дополнениями автора перевода.
Содержание
Что потребуется
- клиентская библиотека google-api-python-client. Подробнее тут
- созданные учетные данные (идентификатор и секретный ключ клиента)
В этой статье показано, как автоматически извлечь весь поисковый трафик и все ключевые слова из Google Webmaster Tool с помощью Python и Google Search Console API. Ниже пошаговое руководство с образцом кода.
Это идеальное решение для SEO-оптимизаторов, работающих на больших сайтах, имеющих много страниц и большое количество ключевых слов.
Вы узнаете, как извлечь более 25000 ключевых слов и автоматически экспортировать данные в CSV-файл. С помощью этого скрипта мне удалось ежемесячно извлекать более 500 тыс. строк данных из GSC API.
Дополнительные ссылки:
- Видеоурок GSC API.
- Полное руководством по Python для SEO
- Руководства по Google Search Console API
Ограничения Google Search Console
GSC — это бесплатный инструмент, предлагаемый Google, поэтому нормально, что они не показывают все данные, так как это был бы очень дорогой процесс. Вместо этого они предлагают вам API.
С GSC вы не сможете получить полный отчет о наиболее эффективных ключевых словах по страницам, странам или устройствам. Данные о эффективности в Google Search Console ограничивают вас 1000 строками данных.
GSC API позволяет создавать отчеты по ключевым словам по страницам, а также позволяет запрашивать все страницы и все ключевые слова, которые можно извлечь из GSC.
Какие данные вы можете извлечь?
API консоли поиска Google имеет три функции: аналитика поиска , карты сайта и сайты .
- Search Analytics — позволяет извлекать подробную информацию из отчетов по эффективности (клики, CTR и показы).
- Карты сайта — позволяет перечислять, добавлять, удалять или обновлять карты сайта.
- Сайты — позволяет получать, перечислять, добавлять или удалять веб-сайты из GSC.
Извлечение всех данных по ключевым словам из Google Search Console
Для тех, кто не привык работать с API, это может быть препятствием для старта, но это не должно вас останавливать, потому что API Google великолепно решает задачи SEO.
Вот шаги по извлечению всех данных о поисковом трафике из API Google Search Console:
- Получить ключ API Google Search Console
- Импортировать библиотеки
- Войти в API
- Сделать запрос к API
Шаг 1: Получить ключ API Google Search Console
Во-первых, вам нужно получить ключ для подключения к API Google Search Console.
Ключ API — это своего рода имя пользователя и пароль, которые вам необходимы для доступа к API.
Следуйте этому руководству, в нем описаны подробные шаги по получению API-ключа Google Search Console.
Вот шаги для получения ключа API Google Search Console:
- Перейдите в консоль разработчиков Google и войдите в систему;
- Создайте проект в Google API
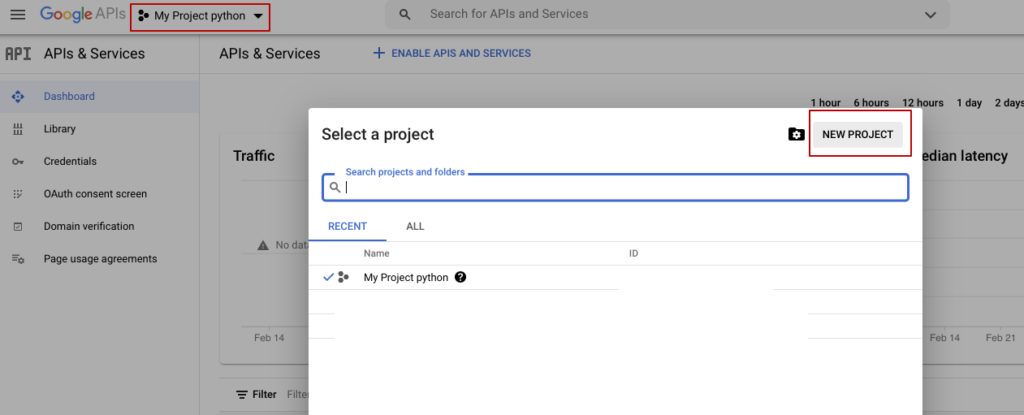
- Перейдите в «Библиотеку» и нажмите «Включить API и услуги»;
- Найдите «API Google Search Console» и включите API;
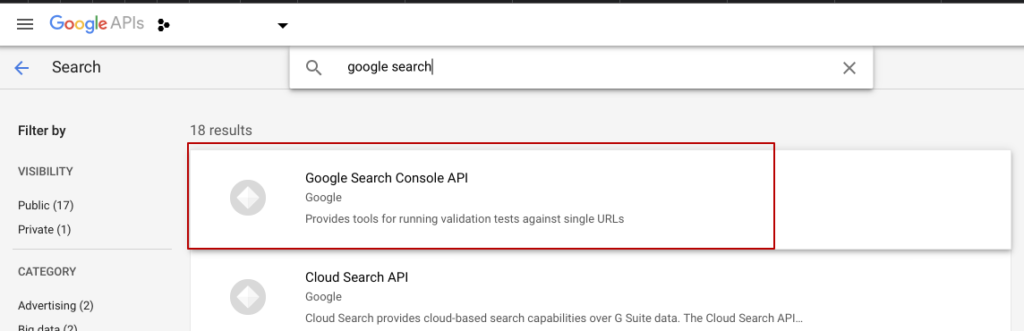
- Перейдите на вкладку «credential», нажмите «create credential» и выберите «OAuth Client ID»;
- Выберите «Desctop app» в качестве типа приложения и нажмите кнопку «Создать»;
- Cохраните JSON-файл с идентификатором и ключом клиента.
Шаг 2: Импорт библиотек
Предварительно установите google-api-python-client
pip install google-api-python-clientВот библиотеки, которые понадобятся для запуска.
import pandas as pd
import datetime
from datetime import date, timedelta
import httplib2
from googleapiclient.discovery import build
from oauth2client.client import OAuth2WebServerFlow
from collections import defaultdict
from dateutil import relativedelta
import argparse
from oauth2client import client
from oauth2client import file
from oauth2client import tools
import re
import os
from urllib.parse import urlparseШаг 3: Создайте каталог для вашего проекта
Цель здесь состоит в том, чтобы использовать добавленный URL-адрес для создания каталога вашего проекта для хранения данных CSV. Эти две функции извлекут доменное имя и создадут проект с использованием доменного имени.
# Get Domain Name to Create a Project
def get_domain_name(start_url):
domain_name = '{uri.netloc}'.format(uri=urlparse(start_url)) # Get Domain Name To Name Project
domain_name = domain_name.replace('.','_')
return domain_name
# Create a project Directory for this website
def create_project(directory):
if not os.path.exists(directory):
print('Create project: '+ directory)
os.makedirs(directory)Шаг 4. Авторизация в API
Теперь, чтобы авторизоваться в API, вам нужно будет загрузить свой ключ API JSON с шага 1 и сохранить его как client_secrets.json в своей рабочей папке.
def authorize_creds(creds):
# Variable parameter that controls the set of resources that the access token permits.
SCOPES = ['https://www.googleapis.com/auth/webmasters.readonly']
# Path to client_secrets.json file
CLIENT_SECRETS_PATH = creds
# Create a parser to be able to open browser for Authorization
parser = argparse.ArgumentParser(
formatter_class=argparse.RawDescriptionHelpFormatter,
parents=[tools.argparser])
flags = parser.parse_args([])
flow = client.flow_from_clientsecrets(
CLIENT_SECRETS_PATH, scope = SCOPES,
message = tools.message_if_missing(CLIENT_SECRETS_PATH))
# Prepare credentials and authorize HTTP
# If they exist, get them from the storage object
# credentials will get written back to a file.
storage = file.Storage('authorizedcreds.dat')
credentials = storage.get()
# If authenticated credentials don't exist, open Browser to authenticate
if credentials is None or credentials.invalid:
credentials = tools.run_flow(flow, storage, flags)
http = credentials.authorize(http=httplib2.Http())
webmasters_service = build('webmasters', 'v3', http=http)
return webmasters_serviceШаг 5: Выполняем запрос
Создадим функцию для выполнения запроса к Google Search Console API.
def execute_request(service, property_uri, request):
return service.searchanalytics().query(siteUrl=property_uri, body=request).execute()Шаг 6: Создание функции для обработки CSV-файлов
Напишим функцию, которая будет сохранять данные в CSV-файл всякий раз, когда будет закончено извлечение данных за определенную дату. Также будем проверить, были ли обработаны даты, чтобы не извлекать одну и ту же информацию дважды.
# Create function to write to CSV
def write_to_csv(data,filename):
if not os.path.isfile(filename):
data.to_csv(filename)
else: # else it exists so append without writing the header
data.to_csv(filename, mode='a', header=False)
# Read CSV if it exists to find dates that have already been processed.
def get_dates_from_csv(path):
if os.path.isfile(path):
data = pd.read_csv(path)
data = pd.Series(data['date'].unique())
return data
else:
passШаг 7: Функция для извлечения всех данных
Данная функция в качестве даты конца выгрузки (end_date) берет текущую дату — 3 дня. Если вам необходимо выгрузить данные за определенный промежуток времени задайте свои start_date и end_date.
Например:
start_date = datetime.datetime.strptime('2021-02-01', "%Y-%m-%d")
end_date = datetime.datetime.strptime('2021-02-28', "%Y-%m-%d")# Create function to extract all the data
def extract_data(site,creds,num_days,output):
domain_name = get_domain_name(site)
create_project(domain_name)
full_path = domain_name + '/' + output
current_dates = get_dates_from_csv(full_path)
webmasters_service = authorize_creds(creds)
# Set up Dates
end_date = datetime.date.today() - relativedelta.relativedelta(days=3) #от текущей даты отнимаем 3 дня, так как данные показывает неточные
start_date = end_date - relativedelta.relativedelta(days=num_days) #начало выгрузки. конеяная дата - num_days заданное количество дней
delta = datetime.timedelta(days=1) # This will let us loop one day at the time
scDict = defaultdict(list)
while start_date <= end_date:
#Проверка что за дату не были выгружены данные ранее
if current_dates is not None and current_dates.str.contains(datetime.datetime.strftime(start_date,'%Y-%m-%d')).any():
print('Existing Date: %s' % start_date)
start_date += delta
else:
print('Start date at beginning: %s' % start_date)
maxRows = 25000 # Maximum 25K per call
numRows = 0 # Start at Row Zero
status = '' # Initialize status of extraction
while (status != 'Finished') : # Test with i < 10 just to see how long the task will take to process.
request = {
'startDate': datetime.datetime.strftime(start_date,'%Y-%m-%d'),
'endDate': datetime.datetime.strftime(start_date,'%Y-%m-%d'),
'dimensions': ['date','page','query'],
'rowLimit': maxRows,
'startRow': numRows
}
response = execute_request(webmasters_service, site, request)
try:
#Process the response
for row in response['rows']:
scDict['date'].append(row['keys'][0] or 0)
scDict['page'].append(row['keys'][1] or 0)
scDict['query'].append(row['keys'][2] or 0)
scDict['clicks'].append(row['clicks'] or 0)
scDict['ctr'].append(row['ctr'] or 0)
scDict['impressions'].append(row['impressions'] or 0)
scDict['position'].append(row['position'] or 0)
print('successful at %i' % numRows)
except:
print('error occurred at %i' % numRows)
#Add response to dataframe
df = pd.DataFrame(data = scDict)
df['clicks'] = df['clicks'].astype('int')
df['ctr'] = df['ctr']*100
df['impressions'] = df['impressions'].astype('int')
df['position'] = df['position'].round(2)
print('Numrows at the start of loop: %i' % numRows)
try:
numRows = numRows + len(response['rows'])
except:
status = 'Finished'
print('Numrows at the end of loop: %i' % numRows)
if numRows % maxRows != 0:
status = 'Finished'
start_date += delta
print('Start date at end: %s' % start_date)
write_to_csv(df,full_path)
return dfШаг 8: Выполнить запрос
site = 'https://site.ru' # Property to extract
num_days = 30 # Number of Days to Extract
creds = 'client_secret.json' # Credential file from GSC.
output = 'gsc_data.csv'
extract_data(site,creds,num_days,output)
#df = extract_data(site,creds,num_days,output)
#df.sort_values('clicks',ascending=False)После вызова функции extract_data в папке, где лежит ваш скрипт, появится папка с csv-файлом с данными по всем поисковым запросам.
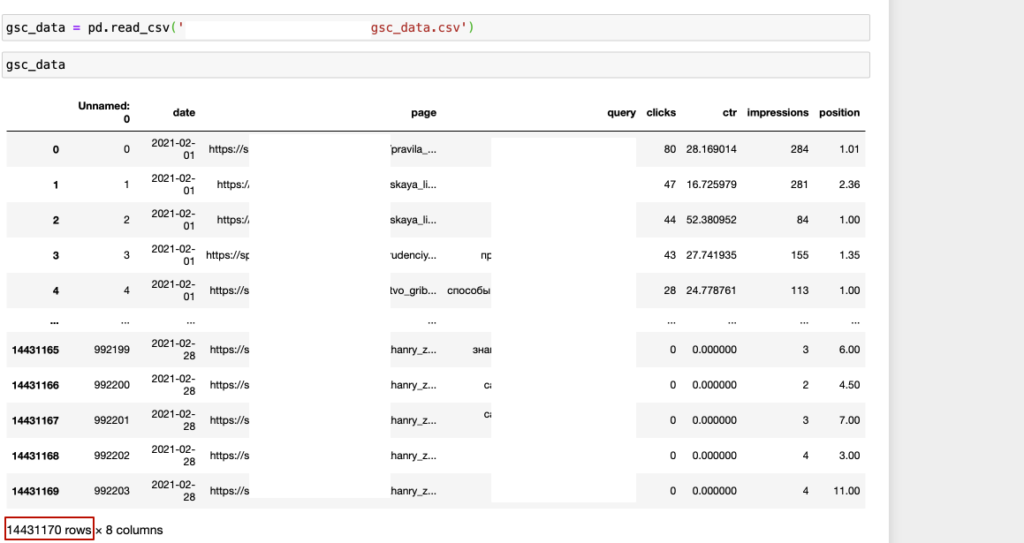
А зачем так заморачиваться, если есть плагин для гугл таблиц?
Если данных немного или нужно выгрузить за небольшой период, плагина , наверно, будет достаточно. На последнем скрине в статье пример выгрузки запросов за 1 месяц ~14млн. строк. Плагином не пользовался, но вряд ли такое получится.